Having explored various approaches to publishing an e-book, as described in my
previous post, I came to the conclusion that I needed to manually produce
Thursday’s Lotus according to an EPUB standard. This meant working directly on the HTML and CSS sources, which I broadly describe here with a little illustration — the discussion assumes some experience of Web development.
To get started, I browsed the KDP online help on
formatting files. The guidance is more about the overall workflow, with only
basic information about HTML. For the details it directs you to the
Kindle Publishing Guidelines, which should serve as the main reference source. I was slow to come across this guide, which helpfully discusses the pathways that I determined in a meandering way for myself, but I don’t think it would have affected the path I took.
However, these guidelines are not so practical as a means to actually learn how to produce EPUB-compliant files as a novice. To fill this gap I bought a copy of Paul Salvette’s
The eBook Design and Development Guide, which is very much a hands-on manual, informative and well laid out. What’s more his company generously provides many helpful
resources for developers, including boilerplates, some of which I used as a basis for my own templates. The main limitation is that it was published in 2012 and oriented around the EPUB2 standard; version 3 of the standard has since emerged and the previous version
IDPF marks as obsolete. Nevertheless, this guide clearly describes the principles behind the EPUB standards, so that I’m quite sure that it will be relatively straightforward to take on board future iterations. Hence I had no hesitation in writing a positive
review. In practice so far I’ve found the online publishers, not just Amazon, readily support this (it’s rather like web browsers will happily display old Web pages, though in most cases this doesn’t go as far as the distracting <blink> tag!)
Document styles in MS Word and Filtered HTML outputs
Salvette is quite adamant that one should write an e-book from the ground up. Certainly it makes for a much cleaner document from the outset. However, on this occasion I acted contrary to his advice, starting with a Word document and exporting it as filtered HTML (but not saving as filtered HTML, which keeps a lot of internal MS Office code and can increase the file size severalfold). One of the reasons I did this was to avoid having to re-enter over 1000 hyperlinked bookmarks in the index or else modify the Word document in ways that are best left to a text editor. Besides, I could learn a lot about the structure of a Word document and its characteristics. I then gradually simplified the HTML. Along the way I realised that the wysiwyg interface made it easy to develop bad authoring habits such as the manual insertion of spaces and the inconsistent use of styles.
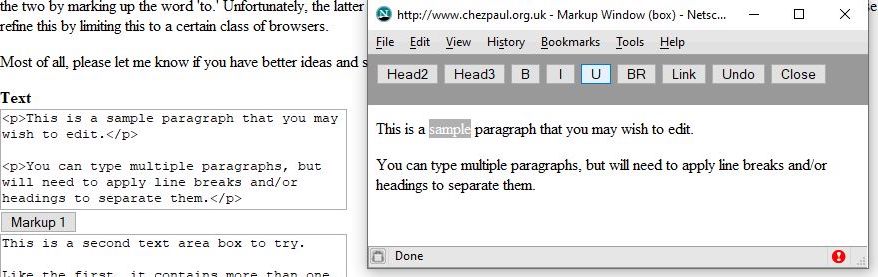
I can illustrate this with a small example.
Thursday’s Lotus includes a glossary of terms with entries in Thai and Romanised Pali (this is included Amazon’s ‘Look Inside’ preview). The first entry is for
Abhidhamma and in Word it looks like:
I had realised that it makes sense to define a style for every distinct type of content, so here I defined one for ‘Glossary Definition’ and chose to display it as indented. The ‘Modify Styles’ dialog, shows these and other details.
An indication of the potential issues that would arise in exporting to HTML becomes readily apparent. For instance, I chose the font face,
Gentium Plus, because it has a classical look that works will on paper and it has broad support for glyphs, including characters with diacritics. However, it’s not included as an option in the Kindle. Underneath the preview window there is a specification of the font support, with explicit reference to Thai language and exact line spacing of 12pt, which I had deliberately chosen as a means to help control the vertical layout because it includes many photographs. These definitions would not make sense for an e-book.
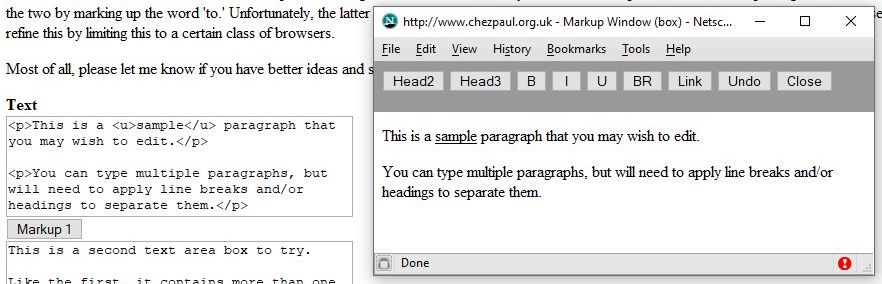
When saved by Word as filtered HTML this glossary item was rendered as:
It’s a little bloated and the use of physical markup tags,
and
, are slightly deprecated, but it is not unmanageable and the main thing is that the structure is sound and it retains all the semantics, including denoting the Thai language instance with a
lang=“th” attribute inside a
tag. In fact, surveying the entire document, it appeared that every Thai language instance was denoted this way — useful because it can be used by browsers, e-readers and so on to interpret Thai content distinctly. One other thing to notice: actually, I had defined two styles: one for the entry term and another for the actual definition, but it became evident that I never got round to using the Glossary entry style.
For a full document, even one that’s of modest sized, the HTML export produces a large single file that can look quite intimidating because the content appears to be engulfed by CSS formatting, starting with masses of font definitions, with numerous built-in Microsoft classes, defining long hierarchies of selectors with many declarations. Furthermore, as even this small example suggests, there was extensive use of
tags, liberally sprinkled across the document. A lot of this very fine-grained control is to ensure precise print-ready documents, most of which is unwanted for reflowable content. But there extraneous material is applied consistently and it’s a matter of understanding the logic of what is applied and how it was applied.
Cleaning and Preparing (X)HTML for EPUB
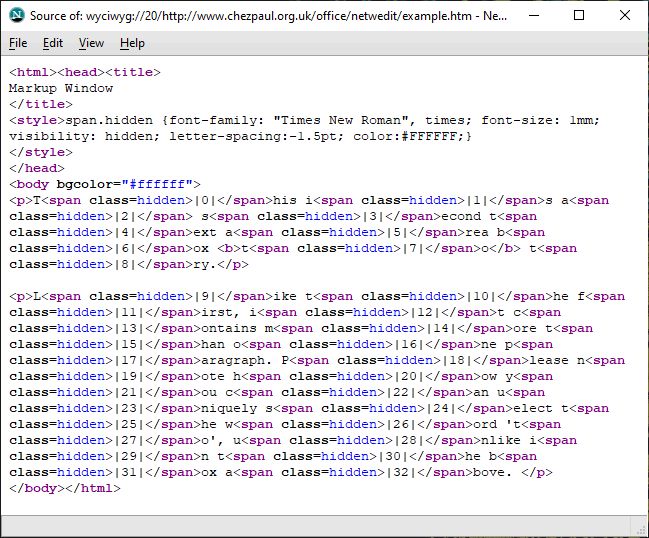
So I then began the process of cleaning the HTML, removing font face definitions, unused CSS selectors (there are tools like
Dust-Me selectors that give the lowdown) and gradually applying regular expression search/replace to successively removing excess spaces. There are quite a few tools available that clean HTML, but for EPUB, there are additional assumptions that can be made that affect what to delete and what to replace. For example, fonts may be converted to use relative sizing (‘em’ units) from fixed points (apart perhaps from titles and headings being positioned relative to top of screen).
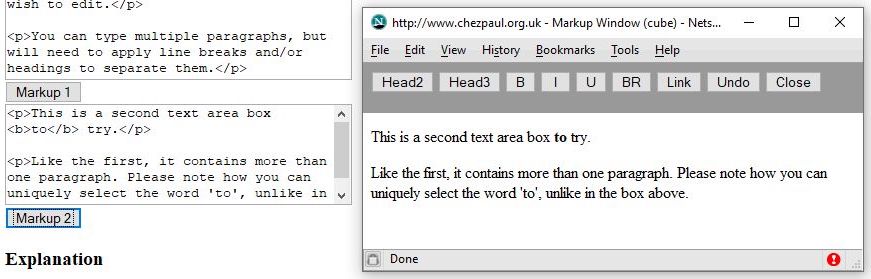
After a number of such transformations the glossary definition became:
I deleted almost all style definitions from the <span> tags, but not the language attribute, whilst declarations that I thought relevant, such as indentation, I folded into the corresponding named classes.
Images
The output also includes a folder of images, which are generally rather small. Compared with the proliferation in the main text, this may seem incidental, but I decided to attend to this early on because the images, of which there are about 100, are an important part of the book. It’s important to note that whereas there’s practically no limit on image file size for CreateSpace and they thus should ideally be of high resolution (Amazon recommends at least 300dpi), there is a caveat with KDP. Depending on the royalty options, the resulting file incurs a region-dependent ‘
delivery cost’, e.g. 10p per MB for books sold in the UK.
To keep costs modest, starting with high resolution sources, I used
Irfanvew to carry out some batch image conversions to output images to have long side with at most 800 pixels and I also applied some compression. The net result was a folder with a total of about 5MB, but I suspect I could have reduced this further because I forgot to strip metadata. It was dealing with issues like this that already indicated it was going to take me a few weeks rather than a few days!
(X)HTML Validation
I initially worked towards
HTML5, with the intention of ensuring that as a late step I correctly serialize this as XML. Only later did I discover that EPUB2 specifies as its
base content format XHTML1.1, whereas
EPUB3 specifies XML serialisation of HTML5, i.e. XHTML5 (aka “polyglot” HTML5). Fortunately, for the relatively simple structure in my book, it meant little more than changing the Web document headers.
For Web standards I generally make a beeline for the World Wide Web Consortium (W3C), which has for a long time helpfully provided an online validator, currently
https://validator.w3.org/nu/. However, after using this repeatedly I felt I ought not to keep draining its resources, so I downloaded and installed a copy from GitHub, via
the project’s About page, following the
instructions to build the service.
One particular error I ran across because of my use of accented characters was:
“Warning: Text run is not in Unicode Normalization Form C.”
This refers to one or more characters that can be generated in multiple ways – notably as a precomposed (single) character or as a decomposed sequence of characters. There are several normalization methods; NFC normalized text, which is recommended for Web pages, opts for precomposed. I found a
helpful thread with a nice solution on Stackoverflow: in
BabelPad just copy and paste across and then select: Convert -> Normalisation form -> To NFC.
EPUB Preparation and Validation
Having refined the HTML, previewed and validated, I then considered the production of the EPUB as a package, i.e. a nested series of folders with sources and metadata. It was time to write some PHP and I loaded up
Netbeans, which is my usual IDE, partly because it is cross-platform. The book itself had to be split into a number of files and so I wrote a script to do that according to sections whilst ensuring that anchors continued to work afterwards. To carry out manipulations on a DOM object created from the single file (before it was split), I used
PHP Simple HTML DOM Parser, and then to assemble the XML files I used the
SimpleXML extension. I created a logical table of contents and also duly specified basic core metadata such as title, publisher, unique identifier and subjects, though I’m not sure how much these are actually used. In addition to Salvette’s guide, I browsed various fora, finding some succinct and sage advice, such as that
from Micah Sisk and others.
For EPUB the final step in packaging is to bundle everything as a ZIP file with a .epub extension; one caveat here is to ensure that the mimetype file is not compressed (there is usually an option available to do this, e.g
-0 for compression-level 0). Then to validate what I had, I turned to the
EPUB Validator, Unfortunately at the times I tried the online service it seemed to be weighed down and couldn’t even complete the processing on the files I submitted. So, as with the W3C validator, I proceeded to download and install my own copy, in this case
epubcheck. Once in place, I had it available to run on the command line and added an alias to .bash_profile for convenience. The tool provides precise feedback about the errors: what they are and where they occur in your code, and with the help of occasional online searches I found all the answers I needed, learning, for example, that every file used in the publication must be included correctly in the manifest!
Conversion to Kindle formats and Preview Tools
Whilst correctness is reassuring, it still remains necessary to inspect what’s presented and I used a number of applications. Even before it gets converted I ran some initial tests on a desktop Web browser. Although this interprets the HTML quite differently, it’s a familiar interface and can highlight issues of inconsistency in fonts and images, notably in their sizes and alignments.
Once I had prepared an ePub file I could then upload to KDP, which carries out a conversion to its own formats and offers a browser-based preview tool. I found it slightly disconcerting process because it would give the impression of some errors that I hadn’t expected. Then I read various comments on fora recommending downloading the resulting .mobi file and a preview application, Kindle Previewer. Furthermore, once downloaded you can use ‘
Send to Kindle’ for a more reliable test on actual hardware. For the conversion, Amazon provides a tool called
KindleGen from various files (as listed in its page on
supported formats). It’s freely available to download and use and comes bundled with the offline previewer. Taken together there are numerous preview options and I don’t think I used them so effectively; next time I need to be more systematic and thorough.
Note there are two versions of KindlePreviewer (2 and 3); working on a Mac, I was reluctant to install
version 2 because of the requirement to use an old version of Java (6) and it seemed a bit fiddly. So I was relieved to find the
beta version 3, which has no such issue and the installation worked fine. It was then a matter of refining the HTML and CSS and rebuilding, which was simple to do with the scripts in place the e-book was ready for publication, well almost...