[This is an article about my explorations of the Internet, particularly some of the tools and applications I've used and developed to foster collaboration and enable broad participation in the 'read/write' Web. It has involved various experiments with software and hence is quite technical in nature. Sorry if it's difficult to understand, but I'm happy to try to explain and clarify.
Updated 2 October 2021 with a section on static and offline search]
I became acquainted with the Internet at the third time (and university) of asking. My first hint came in 1988, as a maths undergraduate at Southampton University. A friend studying computer science showed me pages and pages of dot matrix printout that he had received by electronic mail from his friend at Warwick University. I was unmoved. The second hint came in 1991, as a maths postgrad at Glasgow University, when another student shared with me the joys of e-mail with friends from abroad, pointing to her computer terminal. Again, I passed.
Two years later, in 1993, as a PhD student in computer science at Kingston University, the Internet was intrinsic to my research and it was then that I dived in; I soon became immersed in e-mail, Usenet Gopher, and another service that seemed to be taking the world by storm, the World Wide Web (or, simply, ‘the Web’).
At that time, I shared a research lab with students from various other disciplines, including Maria Winnett, who specialised in Computer-Supported Cooperative Work (CSCW). Although I did not know it at the time, these kinds of initiatives were just further iterations of ongoing efforts over the decades, as exemplified by Douglas Engelbart’s ‘Mother of All Demos’ given in 1968 (in brief / in full), and later reflected on, inspired in turn by Vannevar Bush’s essay of the '40s “As We May Think”. Furthermore, these approaches would, perhaps unconsciously, influence some of my own work.
Tim Berners-Lee had conceived and implemented the Web only a few years before. A core part of his vision was that the Web should be read/write; the first browser was thus a browser-editor, called WorldWideWeb. Whilst most of the ingredients were in place — the http protocol, HTML, Web browser and httpd server — some aspects were not complete. For instance, his editor could only ‘write’ to local files; the HTTP PUT request method was yet to be devised (more about this later …)
I first explored the Web using NCSA Mosaic, which I also used to take some baby steps in authoring my first HTML markup using its Personal Annotations feature. I then started contributing to departmental pages and I was on my way, but my usage was conventional and most of my attention was on my own research.
OSS Wisdom and Easy Web Editing
Whilst I had been using Unix (Solaris) for my research, I wasn’t really cognisant of free and open source software until I started preparing for my first full time job in 1998 at the University of Derby. I took over the technical development of
MultiFaithNet, an online gateway to religious resources. The site was needing a new home; I was asked to set up and maintain a new server, of which I had zero experience. Faced with a dwindling budget, I bought a book on RedHat 5.1, a distribution of the Linux operating system, and installed it on my home computer off the accompanying cover CD. I acquainted myself with the main components, including the Apache httpd web server, CGI/Perl and regular expressions. PHP and MySQL came a bit later.
The site contained a mixture of informational content and community-oriented facilities. The project team maintained editorial control with some pages retaining the same structure, but being revised on a fairly frequent basis. Team members really wanted something as easy to use as a word processor without having to know HTML or worry about the technicalities of uploading to a server. Netscape anticipated such demand with
Netscape Composer, which added editing facilities to its
Navigator browser. It provided a WYSIWYG interface, making it amenable to all my colleagues, who were not concerned with the underlying HTML that it generated.
There remained the problem of how to enable an easy means to upload edited files to the server. I found a solution thanks to the introduction of the PUT request method, in the
HTTP/1.1 specification of the international Web standards. Such a facility had been missing when Sir Tim was first editing web pages using WorldWideWeb (they could only be updated locally under the file URI scheme). The
provision of PUT was a pivotal step in opening up the read/write web and, on the client side, support was quickly added to Netscape Composer.
Accordingly, I followed the guidance and implemented support for PUT request method on the server. However, as the Apache Week article intimates, it came with risks and soon become deprecated, so I secured it with various measures, as per the article, with IP address restrictions for good measure.
Annotations in CritLink
MultiFaithNet was a platform for dialogue and engagement. To support this paradigm in the technology infrastructure, I explored web annotations and came across
CritLink (and the wider toolset, CritSuite), a
project of the Foresight Institute developed by Ka-Ping Yee. It used a proxy server approach to add comments non-invasively with a rich feature set, including bi-directional links, that are not supported in the Web.
I quickly felt it had a lot of potential to support collaborative working, and downloaded and installed it on MFN with the aim of encouraging internal use to begin with. I also contacted Ka-Ping Yee to give some encouragement, suggesting that he present his work in the field of CSCW. Perhaps already having this in mind, he duly
delivered a paper. As I started speculating about what lessons might be learnt about free and open source software, I mentioned CritSuite in
Open Sources: A Higher Consciousness in Software Development, a paper I gave at an unusual conference,
To Catch the Bird of Heaven, which hosted various perspectives on wisdom.
However, these initiatives subsequently came to a halt as funding for the
MultiFaithNet project dried up and I needed to find other employment. The uptake of CritSuite failed to gain critical mass, partly because of lack of resources (reflected in the Crit.org server often struggling with poor performance) and partly because some rivals took some of the limelight. However, of probably greater bearing was that larger organisations took exception to having anyone provide ‘frank’ comments, which they regarded like graffiti. There was no moderation (apart from the facility to comment on comments). Nevertheless, among those willing to give CritLink a try, it gained
considerable respect.
NetWedit: A WYSIWYG Web editing widget
Today, it’s fairly easy for anyone to create and maintain their own websites. Probably the majority of web content is written and updated through web forms, much of it in content management systems such as WordPress, which accounts a large proportion of all web sites. It was designed as a blogging platform, as such a major step to read/write web according to Sir Tim, when
interviewed by Mark Lawson for the BBC in 2005.
Blogging consists not only of jotting down one’s thoughts, as in a manuscript, but presenting it as a Web document. A key enabler, usually powered by JavaScript, is the WYSIWYG editing box. It is now taken for granted, but twenty years ago, Web editing wasn’t so amenable. Whilst there were sporadic attempts to realize
in situ editing via the browser’s own client, as I had explored with HTTP PUT, the normal procedure for updating websites was more convoluted. Typically, an author would write copy and send it to someone with technical skills to prepare a web version on their PC using an authoring tool such as
Dreamweaver or else hand code the HTML and CSS. Then the files were transferred in a separate process via ftp and finally reviewed by the original author.
However, by the turn of the century, database-driven content management systems (CMS) were already emerging, where it was no longer a matter of editing individual pages, but instances of data that were supplied to templates. Some CMS had large numbers of users who each needed to maintained a few paragraphs and update them whenever they liked. I was faced with such a situation after I had moved down to Oxford to join the
Humanities Computing Unit: as part of an online teaching resources database system, theologians needed a simple way to edit some content through the web-based.
With necessity being the mother of invention, I released my first open source contribution in 2001 under LGPL – I’m not a great fan of 'infective' licenses. :-/ It was a rich text editing widget called
NetWedit, designed for Netscape Navigator (version 4, upwards) and also supported by Mozilla0.9+, and IE4+ (Windows only). It gained some exposure in HEI after its inclusion in Paul Browning’s
TTW WYSIWYG Editor Widgets list. Apart from the Java solutions, all the other entries on the list would only work on one operating system or in one browser; NetWedit was possibly the world’s first non-Java-based cross-browser solution, albeit not fully cross-platform.
Implementation
I was not a JavaScript guru, so I chose the path of least resistance, targeting the
textarea HTML input area, which is generally used as a form element for more substantial amounts of text. For users to make dynamic updates without server-side scripting, I figured that I needed editing to take place in a pop-up window, whilst storing the HTML source in the textarea box of the parent window. I realised that dealing with user interactions, especially changes to content, would be a complex process, so I settled on a workflow process whereby the user would type text (without markup) in the boxes and then press a button to launch a pop-up, in which to then carry out the markup (formatting, links, etc.). So, it’s more accurate to say that NetWedit is a
markup tool.
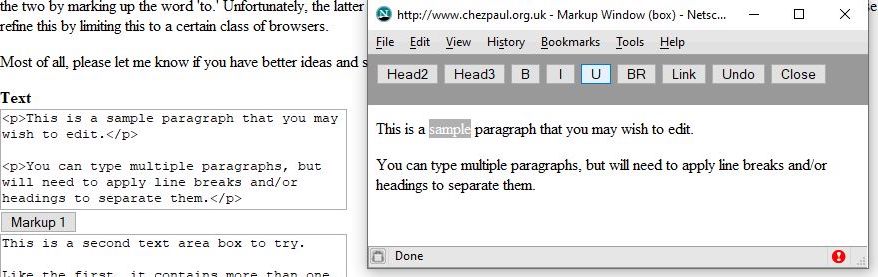
Once I had figured this approach, the implementation was quite neat. The code consisted of a single JavaScript library file. When loaded on a given page, any number of form textarea elements could be enabled for WYSIWYG markup. Here’s an extract from a sample page with two editable areas.
To the left you can see a bit of text followed by a couple of textarea boxes in a Web form. These boxes are actually the HTML source views. Normally with rich text editors, we see either the source view or the rich text view, not both, but a feature of NetWedit is that you can see both side by side. It’s thus a handy instructional tool.
I’ve pressed the [Markup 1] button to launch a markup window. In fact, launching the window itself already showed the use of the <p> tag.
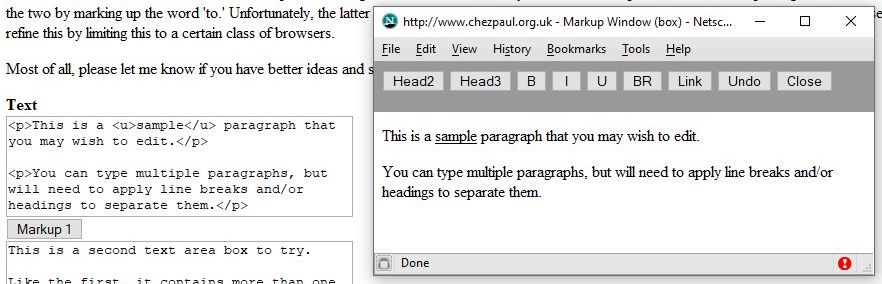
Any markup applied in the popup was instantly reflected in the source windows, thereby offering interesting possibilities to learn the markup. Thus, highlighting the word, ‘sample’, and pressing the [U] button is instantly reflected as follows:
As mentioned above, this ‘editor’ didn’t actually allow edits to the text itself - these had to be done in the source textarea.
Visual Shenanigans
Subject to the
Document Object Model at that time, there was only one method to capture user-selected text,
document.getSelection(), which returned a string. Later
revisions, returned an object and allowed one to determine exactly where in the DOM the selection was made. However, here there was no immediate method to locate its whereabouts - if you selected ‘the’, which ‘the’ was it? There was nothing more granular.
I got round the limitation by using a kind of visual deception through (an abuse of) CSS, inspired by WordPerfect’s ‘
reveal codes’. Using the
<span> tag, I inserted a unique sequence of characters after the first character of each word, hidden by a CSS setting of zero display width. When selecting the intended word,
getselection() would include the invisible characters, so that when it came to identifying a particular instance of a word, the system was actually searching for a unique word.
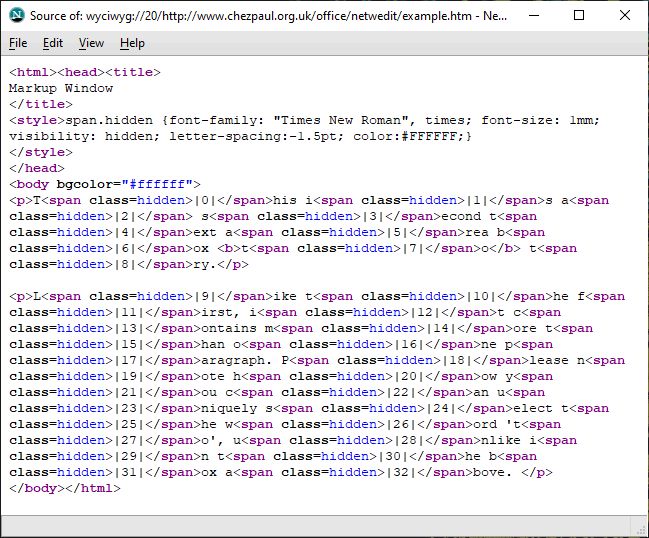
All is revealed by viewing the frame source for the text being marked up:
Behold the generated code in its marked-up glory! Note especially the fragment, <b>t<span class=hidden>|7|</span>o</b>,
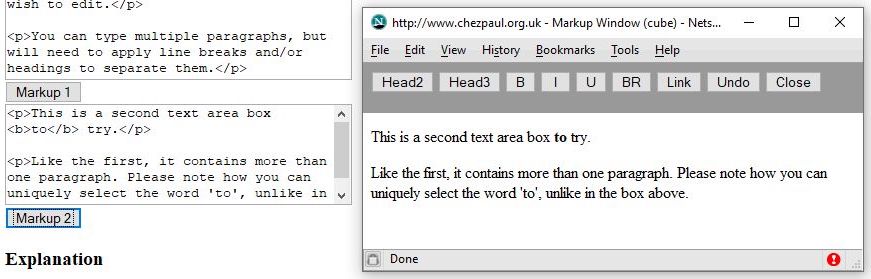
But none of this formatting was applied to the source, so only the intended markup, <b>to</b>, was retained:
The widget was successfully deployed in the
Theology Faculty Teaching Resources site, where Faculty could maintain their own profiles – research interests and publications. It was considered simple to use and was all that was needed at that time.
I also received quite a bit of response to the release of the software, especially in the first year or two, when it was tried in custom web-based content management systems (WordPress wasn’t released until 2003). I even wondered about deploying it in CritSuite to make it easier to make granular text selections. However, as browser support became more comprehensive, more sophisticated solutions such as
FCKEditor came along (also in 2003), and I knew I would have to take a back seat, though I did try to up my game with
RTWedit.
Alas, my editing widgets don’t work in any modern browsers, because the method I used was superseded, though I guess it’s just a matter of working out what the new methods are (and hopefully, there’s no new security constraint). However, it's still possible to see NetWedit, as released in 2001, working on Windows 10: download Netscape 9 from
an archive and then launch Navigator and load the
page from the Wayback machine (under plain http).
The Aesthetics of XML editing via XSLT
The problem with HTML is that it became increasingly about presentation, despite being in fact
a special instance of SGML, designed for documents in general and their semantics (think about how to encode Shakespeare!) This fact was emphasized by colleague in the HCU, especially by its Director,
Lou Burnard, and his expert assistant,
Sebastian Rahtz. These were authorities
on semantic markup and had a great influence on web developments at OUCS.
I discovered this when working on
Interactive Audio Comprehension Materials (IACM), a web-based system to train students in various modern languages by listening to passages and answering questions to check their understanding. The data – passage content and multimedia timings – was stored entirely in XML. With Sebastian's help, another team member, Paul Groves, had already developed a delivery system using Perl’s XML:Sablotron, but now the Faculty wanted to add a web-based editing system.
So I devised a system that took user’s web form input and turned it into
custom XSLT to transform the XML to XML. As I later
reflected, it had the nice aesthetic property of being amenable to recording not only changes to data, but how those changes were made. I showed this solution to Sebastian, who was intrigued and, characteristically, almost immediately wondered whether it could handle more complex scenarios. But a need didn’t arise.
Ingredients for Innovation and Collaboration
OUCS was a very collaborative environment; it helped that almost everyone had a certain level of technical competence and many were experts in their field, so exchanges were fruitful. Everything was available in-house – from R&D to hosting and administration, which facilitated greater exploration and faster turnarounds.
The department was prepared to experiment and take risks, which yielded a lot of innovation. In particular, Sebastian
architected the OUCS web site based on TEI XML. It meant all staff having to learn TEI, which required some effort, but at least that could author content using an editor of their choice, ranging from
vi to
XMetaL. However, once the documents were written, the system effortlessly delivering HTML, PDF and many other documents
using Apache Axkit.
OUCS is now
history, along with many of the processes, systems and services that were developed. Nowadays, the content and presentation of departmental websites are more managed and controlled. The presentation is more visual, yet the result seems to me to be increased homogeneity, not only in look and feel, but in the kind of content. It reads well because it’s edited for a general audience, yet it feels intellectually less exciting, lacking some freshness and spontaneity.
Nevertheless, aware of cycles in development, I remain optimistic as upward spirals are always possible. Looking at annotations, among the
various initiatives, it looks like
Hypothes.is is gaining traction and keeping the spirit of collaboration of the early pioneers. There are still some good prospects for a truly read/write Web.
Offline Search for Content Management Systems
Core to ‘read’ing the web is search, another facet we can delve into.
Again in 2001, I became involved in the development of a multimedia Chinese language learning system, featuring a range of interactive exercises. It was implemented as a website driven by CGI/Perl. I was asked to ‘put it on a CD’, with the option to support further updates to its contents. I eventually delivered a production system, with admin facilities, that output
a static site according to a specified folder hierarchy. There was, however, one wish that I never got round to fulfilling – a search function. The most promising cross-platform solutions available at the time were mainly based on Java, but I couldn’t manage to incorporate them.
Almost twenty years later, 2020, I am using WordPress and have almost the same requirement – I wish to generate a static version of a WP site that I can search offline. Surely, there’s a nice plugin available?
I duly wandered over to
WordPress plugins directory. After a while, it became evident that the search facilities that were available required some server infrastructure, whether that was the use of a third party service like
Algolia or some experimental
‘serverless’ solution, All of these, whether ‘scriptless’ or otherwise, still require server infrastructure, even if the site itself is fully static. They are no use for a searching a static site on a memory stick when you have no Internet.
Looking for something that I might (legally) adapt for my purposes, I found
WP Static Search, a plugin that looked far more promising, being built on an established JavaScript package, Lunr.js. Again, the author is a developer who is working with this kind of technology in commercial applications and it turned out that it had some bugs; and the author hasn’t yet responded to suggested fixes. Even so, I could make these changes myself by forking the repository on Github.
After applying the fixes, I then tackled the requirement to make this work offline (without reference to any server). The key to this was to take account of the JavaScript security model’s restriction on loading files – basically, any file like a search index cannot be loaded in the usual way. So, the index had to be incorporated in the library itself, in one of the JavaScript files. Thus, I modified the index-builder to write the index inside lunr-index.js itself. I’ve published the modified code on GitHub:
https://github.com/paultraf/wp-static-search . You can go ahead and download the master zip, but then rename it wp-static-search.zip before installing in WordPress.
It’s rudimentary, but it works. I use it for the
Sigala Research site, in conjunction with wget, which creates the static version for me.




 Today was officially my last day as Web Officer at
Today was officially my last day as Web Officer at 